А question that I answered получил мне интересно:Очередные подробности реализации выражение
Как регулярные выражения реализованы в Python? Какие гарантии эффективности существуют? Является ли реализация «стандартом» или она может быть изменена?
Я думал, что регулярные выражения будут реализованы как DFA, и поэтому были очень эффективными (требующими не более одного сканирования входной строки). Laurence Gonsalves поднял интересный момент, что не все регулярные выражения Python являются регулярными. (Его пример равен r "(a +) b \ 1", который соответствует некоторому числу a, a b, а затем тому же числу a, что и раньше). Это явно не может быть реализовано с помощью DFA.
Итак, чтобы повторить: каковы детали реализации и гарантии регулярных выражений Python?
Было бы неплохо, если бы кто-то мог дать какое-то объяснение (в свете реализации) относительно того, почему регулярные выражения «cat | catdog» и «catdog | cat» приводят к различным результатам поиска в строке " catdog ", как указано в question that I referenced before.
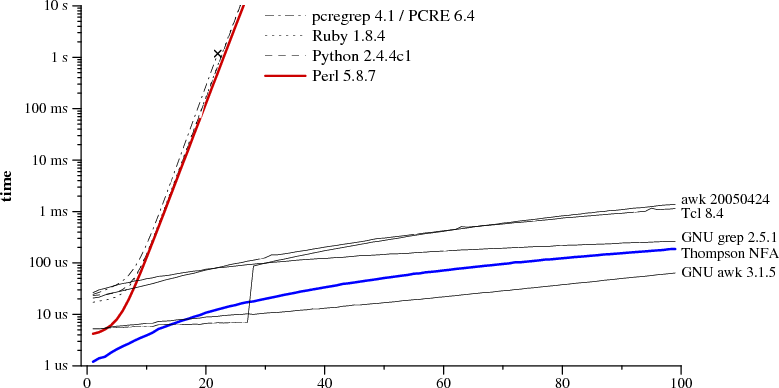
Сегодняшние реализации регулярных выражений имеют гораздо больше возможностей, чем описывает классическое определение регулярных выражений. – Gumbo
@Gumbo: Действительно, они ... это своего рода причина для моего вопроса. Мне интересно узнать о конкретной реализации, потому что на самом деле небезопасно предполагать использование DFA (из-за этих дополнительных возможностей). – Tom
Используйте источник, Люк (http://svn.python.org/view/python/trunk/Lib/re.py?view=markup). На самом деле это выглядит достаточно хорошо документированным. –