Регулярное выражение, которое соответствует каждой из последовательностей слов будет:
(?:\b\w+(\w)\b[\W]*(?=\1))*\1\w+
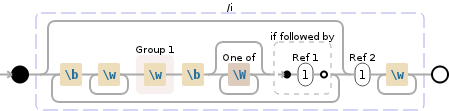
Вам нужно настроить \W часть в зависимости от ваших правил, касающихся полных остановок, полуколоний, запятых и т. д.
Обратите внимание, что это также предполагает единственную букву слова прерывают последовательность.
Вы можете затем цикл над каждым из вхождений и найти самый длинный:
try {
Regex regexObj = new Regex(@"(?:\b\w+(\w)\b[\W+]*(?=\1))*\1\w+", RegexOptions.IgnoreCase | RegexOptions.Singleline);
Match matchResults = regexObj.Match(subjectString);
while (matchResults.Success) {
// matched text: matchResults.Value
// match start: matchResults.Index
// match length: matchResults.Length
// @todo here test and keep the longest match.
matchResults = matchResults.NextMatch();
}
} catch (ArgumentException ex) {
// Syntax error in the regular expression
}
// (?:\b\w+(\w)\b[\W]*(?=\1))*\1\w+
//
// Options: Case insensitive; Exact spacing; Dot doesn’t match line breaks; ^$ don’t match at line breaks; Numbered capture
//
// Match the regular expression below «(?:\b\w+(\w)\b[\W]*(?=\1))*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Assert position at a word boundary (position preceded or followed—but not both—by a Unicode letter, digit, or underscore) «\b»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
// Match the regex below and capture its match into backreference number 1 «(\w)»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w»
// Assert position at a word boundary (position preceded or followed—but not both—by a Unicode letter, digit, or underscore) «\b»
// Match a single character that is NOT a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «[\W]*»
// Between zero and unlimited times, as many times as possible, giving back as needed (greedy) «*»
// Assert that the regex below can be matched, starting at this position (positive lookahead) «(?=\1)»
// Match the same text that was most recently matched by capturing group number 1 (case insensitive; fail if the group did not participate in the match so far) «\1»
// Match the same text that was most recently matched by capturing group number 1 (case insensitive; fail if the group did not participate in the match so far) «\1»
// Match a single character that is a “word character” (Unicode; any letter or ideograph, digit, connector punctuation) «\w+»
// Between one and unlimited times, as many times as possible, giving back as needed (greedy) «+»
Что о попытке что-нибудь! Кроме того, реализация этой функции с немного большим количеством кода (с петлями) кажется довольно простой. – varocarbas
Я согласен с @varocarbas, кажется, что это проще сделать с циклом, а не пытаться адаптировать регулярное выражение. – test
regex ... кошмар. Напишите от руки это на любом языке. Я думаю, что это можно решить в O (N). RegEx не подходит для поиска значения «max» ... RegEx хорош для поиска шаблонов, а не максимальных значений или минимальных значений. –