Я работаю над созданием файлового сервера, который может снять нагрузку с основного веб-сайта и обслуживать изображения/файлы через Интернет для клиента.Подходы к созданию файлового сервера
Основные задачи файлового сервера:
- Сними нагрузку с основного сервера хостинг сайта
- Повторное использование существующего кода веб-сервер базы и избежать дублирования кода/логики для лучшей ремонтопригодности
- Будучи масштабируемой для увеличения downloads
- Скрыть реальный путь загрузки URL-адреса от пользователя
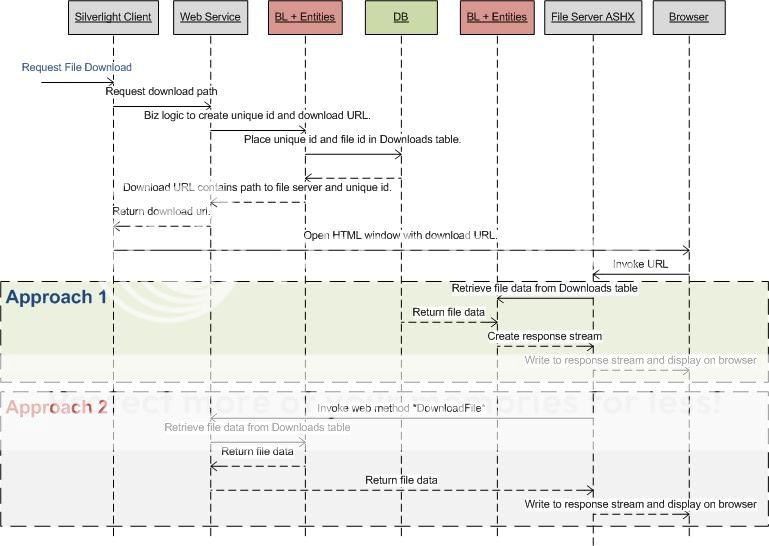
Имея в виду выше, я мог бы придумать два подхода. Представление схемы последовательности двух подходов для удобства понимания [извинения за искаженное использование диаграммы последовательности]. Ни один из подходов не будет удовлетворять всем моим целям.
Какой из этих подходов вы бы рекомендовали рассмотреть мои цели?
Есть ли лучший третий подход?
Некоторые различия, я мог думать:
- Подход № 1 приведет к дублированию кода BL вызывает ремонтопригодность вопросы
- Подход № 2 будет повторно использовать код и централизовать BL восстанавливающий ремонтопригодность вопросы
- Approach # 1 будет уменьшать количество сетевых вызовов, в то время как # 2 увеличивает их
Концепция файловых серверов, масштабируемость загрузок, распределение полосы пропускания все время были там некоторое время. Пожалуйста, поделитесь своими мыслями!
ОБНОВЛЕНО:
Подход № 1 выглядит очень привлекательно, как он принимает нагрузку с основного сервера полностью. Единственная проблема, с которой приходится обращаться в # 1, - это проблемы с дублированием кода и ремонтопригодностью. Это можно было бы преодолеть, имея только один проект для BL/DAC, содержащий функциональные возможности, необходимые как для веб-службы, так и для файлового сервера. И ссылайтесь на сборку/библиотеку в проектах веб-сервиса и файлового сервера. Теперь есть только один код BL/DAC для поддержки, а также избегает сетевых вызовов в подходе №2.
{kind=link}
@Jaimal: По файлам я имею в виду документы, хранящиеся на веб-сервере/db, которые были загружены пользователем. Цель состоит в том, чтобы сделать его масштабируемым позже для размещения в центре обработки данных. – pencilslate
@Pencilslate: Хм, при загрузке, перепишите имя файла с помощью guid, в котором трудно прочитать URL-адрес и уникальный уникальный URL 99,99%, напишите файл на отдельный сервер. Храните указатели в индексированном столбце в db вместе с другими метаданными (размер имени файла, дата даты и т. Д.). Затем, когда файл запрашивается, возьмите файл с помощью guid.Вы можете быстро переписать имя файла на его оригинал при отправке потока повтора. Таким образом, вы создали свое уникальное имя файла и, следовательно, уникальный URL-адрес d/l и не должны создавать его во время запроса. –