Все надуманные примеры, которые я нашел из свертки в распознавании признаков, «упрощают» операцию свертки, имея значения пикселей 1 или -1. Это делает для очень простой операции (умножать входной пиксель фильтровального пикселя, результаты суммы, а затем разделить на количестве пикселей):Какая операция свертки используется для распознавания изображений?
Однако, это не очень полезно для большинства изображений, где значение пикселей будет иметь диапазоны , Например. (0,0-1,0) или (0-255).
Я не могу найти пример, какой алгоритм использовать для этих входных значений. Я попытался суммировать разницу для каждого пикселя, а затем делить на количество пикселей, чтобы получить общую «ошибку». Активация тогда равна max - ошибке. Например. 255 - ошибка, или 1.0 - ошибка.
Он никогда не выдаст отрицательного значения, хотя я не вижу необходимости в слое ReLU. Это заставляет меня подозревать, что это наивный подход и на самом деле не работает, но я не уверен, почему.
Итак, какова операция, используемая, когда входные данные являются чем-то иным, чем 1/-1?
EDIT Вот пример я смотрел на: http://brohrer.github.io/how_convolutional_neural_networks_work.html
И операция свертки он описывает:
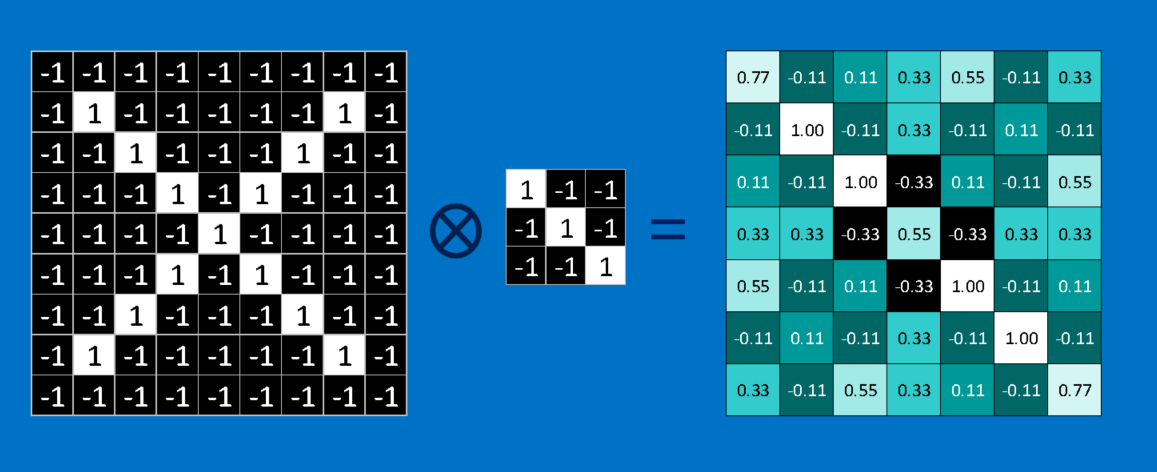
Чтобы вычислить совпадение признака в пятне изображения, просто умножьте каждый пиксель в функции на значение соответствующего пикселя в изображении. Затем добавьте ответы и разделите общее число пикселей в этой функции. Если оба пикселя белые (значение 1), то 1 * 1 = 1. Если оба являются черными, то (-1) * (-1) = 1. В любом случае каждый соответствующий пиксель приводит к 1. Аналогично, любой Несоответствие равно -1.
Конкретный пример того, почему я не думаю, что это работает для пикселей со значением [0.0,1.0]. Скажем, у нас есть фильтр 1x1 со значением [0.5]. Если мы запустим это по входному пикселю, значение которого равно 0.5, тогда получим 0.25.
Аналогичным образом, если мы используем диапазоны цветов [0,255], тогда мы легко получим значения> 255. Хотя я не уверен, что имеет значение, поскольку данные больше не являются пикселями; это активация в карте объектов, не так ли?
Да, я понимаю, как свертку фильтра через вход. Я предполагаю, что я говорю, неясно, как это работает, если каждый из ваших входных пикселей имеет диапазон значений, а не двоичный 1/-1. Я отредактировал вопрос, чтобы включить пример, который я использую для этого. –
Разделите на 1/(сумма всех этих чисел) – Tatarize
Независимо от того, какие весы вы используете, их необходимо нормализовать или предварительно определить. Поэтому добавьте вес, чтобы взвесить сумму. Это немного похоже на среднее значение всех этих значений над суммой весов. – Tatarize