У меня есть некоторые выражения регулярных выражений для размещения содержимого между тегом, как видно из результата. Если я применить то же регулярное выражения выражения по приведенному тексту я буду получать тег внутри тегов ...Совпадение не между тегами
Оригинального содержания:
Lorem Ipsum 123456 Dolor сидеть @twitter Амета, consectetur adipiscing Элиты примера.
РЕЗУЛЬТАТ:
Lorem Ipsum [тел] 123456 [/ тел] Dolor сидеть [TW] @twitter [/ Tw] Амет, consectetur adipiscing Элит [а] пример [/ а].
РЕЗУЛЬТАТ ВТОРОЙ РАЗ:
Lorem Ipsum [тел] [тел] 123456 [/ телефон] [/ тел] Dolor сидеть [TW] [TW] @twitter [/ TW] [/ tw] amet, consectetur adipiscing elit [a] [a] пример [/ a] [/ a].
Что добавить в выражения регулярных выражений, чтобы они не совпадали, если контент находится между любыми [] и [/]?
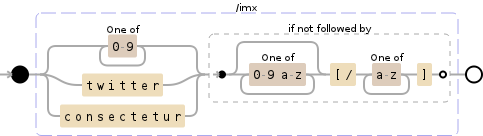
Попробуйте добавить '(?! \ [\/[^]] *])' до конца ваших шаблонов регулярных выражений. –
Ответ ниже - обходной путь, а не решение. –