NVIDIA предлагает GPUDirect для уменьшения накладных расходов на передачу данных. Мне интересно, есть ли аналогичная концепция для AMD/ATI? В частности:Предлагает ли AMD OpenCL нечто похожее на GPUDirect от CUDA?
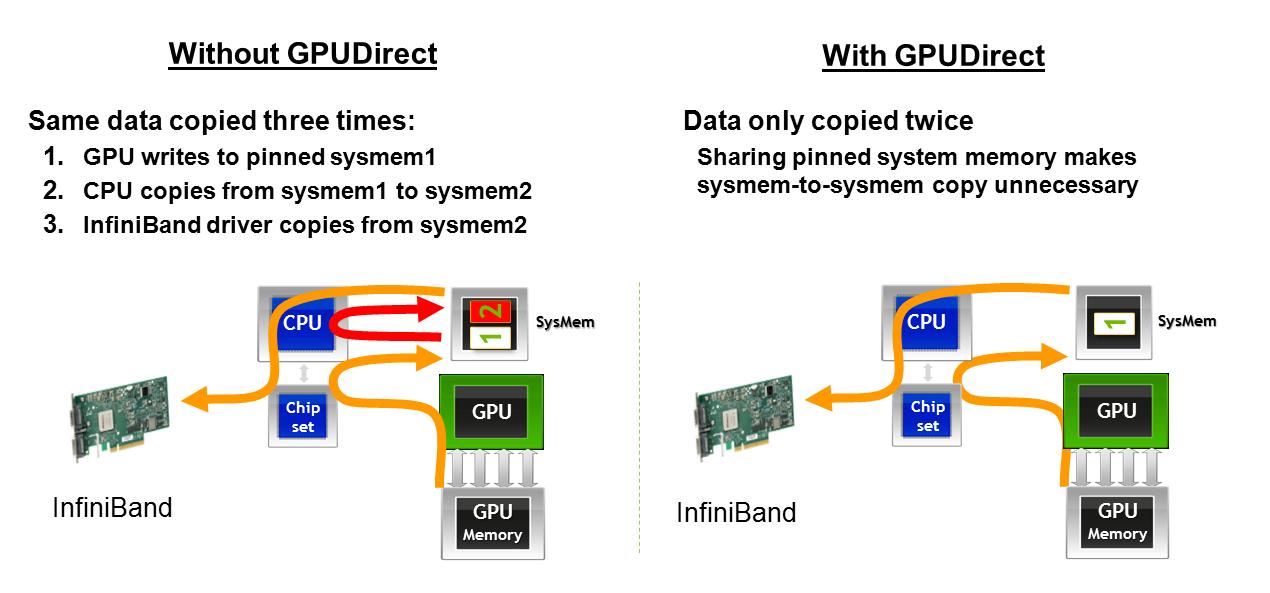
1) Могут ли GPU AMD избежать второй передачи памяти при взаимодействии с сетевыми картами, as described here. В случае потери графика в какой-то момент здесь приводится описание воздействия GPUDirect на получение данных с GPU на одной машине, которая будет передаваться по сетевому интерфейсу: с GPUDirect память GPU переходит в память хоста, а затем прямо в сеть интерфейсная карта. Без GPUDirect память GPU переходит в память хоста в одном адресном пространстве, тогда CPU должен сделать копию, чтобы получить память в другое адресное пространство адресной памяти хоста, а затем она может выйти на сетевую карту.
{kind=link}
2) Графические процессоры AMD позволяют передавать память P2P, когда два графических процессора совместно используются на одной шине PCIe, as described here. В случае потери графика в какой-то момент здесь описывается влияние GPUDirect на передачу данных между графическими процессорами на одной и той же шине PCIe: с помощью GPUDirect данные могут перемещаться напрямую между графическими процессорами на одной шине PCIe, не касаясь памяти хоста. Без GPUDirect данные всегда должны возвращаться к хосту, прежде чем он сможет перейти на другой графический процессор, независимо от того, где находится этот графический процессор.
{kind=link}
Редактировать: BTW, я не совсем уверен, сколько GPUDirect является утилитой для пачек и сколько это действительно полезно. Я никогда не слышал о том, как программист GPU использует его для чего-то реального. Мысли об этом тоже приветствуются.
Не могли бы вы предоставить текстовое описание двух технологий в случае связанных рисунков снесенных на более позднем этапе? Кроме того, я считаю, что второй график неясен относительно того, что предлагается. – James
James, это сделано. – arrayfire
@gpu: mvapich2 имеет прямую поддержку GPU в своих последних выпусках, я использовал его, и он работает быстрее - вы можете вызывать 'MPI_Send' и' MPI_recv' и передавать указатели памяти GPU в качестве аргумента, и все «просто работает». – talonmies