Я хочу заменить все из списка, который НЕ соответствует данному шаблону. Я использую R версии 3.1.3 (2015-03-09) - "Smooth Sidewalk"Выделить все, кроме определенного регулярного выражения, из списка в R
Список примеров у меня есть:
y <- c("D CCNA_This is example 1 bis", "D CCNA_02345 This is example 2", "D CCNA_12345 This is example 3", "D CCNA_23468 This is example 4")
и образец, который я хочу, чтобы соответствовать это CCNA_, где числа не совпадают в каждом случае, но всегда имеют 5 цифр.
Нужный выход:
"CCNA_" "CCNA_02345" "CCNA_12345" "CCNA_23468"
до сих пор я удалил предыдущую часть на матч по:
y_begin_rm <- sub("D ", "", y)
, но у меня есть проблемы в признании матч с [^ матча] выражение.
y_CCNA_numbers <- sub("[^CCNA_[0-9][0-9][0-9][0-9][0-9]]*$", "", y_begin_rm)
, который производит вывод:
[1] "CCNA_This is example 1 bis" "CCNA_02345 This is example 2"
[3] "CCNA_12345 This is example 3" "CCNA_23468 This is example 4"
кажется, что проблема число, указанное в матче смотрится полностью через строку, а не в точной комбинации, что я хочу. Таким образом, число после фразы «это пример» вызывает много проблем. Когда я опускаю цифры или поместить цифру, только после CCNA_string она работает просто отлично:
y_CCNA <- sub("[^CCNA_]*$", "", y_begin_rm)
reults в
[1] "CCNA_" "CCNA_" "CCNA_" "CCNA_"
или
y_CCNA_0 <- sub("[^CCNA_0]*$", "", y_begin_rm[1])
результатов в
[1] "CCNA_0"
Есть ли способ спецификации ify точный шаблон, который я ищу (CCNA_ [0-9] [0-9] [0-9] [0-9] [0-9])? Кроме того, существует ли возможный способ сделать это за один шаг (удалить до и после матча в одном регулярном выражении)?
Заранее благодарен!
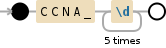
Я думаю, вы имели в виду stringR/stringi? :) – Molx
regmatches (y, regexpr ('CCNA _ \\ d {5}', y)) –
@ShenglinChen есть ли что-нибудь, что вы пытаетесь сказать здесь? –