Я тестирую свое регулярное выражение в https://regex101.com/ перед выполнением каких-либо кодировок.Regex катастрофическое возвращение назад, когда не соответствует
Regex:
\[(.*?)\]((?:.\s*)*?)\[\/\1\]
Пример строки:
[tag1] Тест в Тест Текст Текст Текст Тест Тест текста.
Тестирование тестового текста Проверка текста «Текст текстового теста» Текст тестового текста.
Тестовый текст? Тестирование текстового теста Текстовый тест Текстовый тест Текстовый тест Текстовый тест Текст.
Тест Текст, Тест Тест Текст Текст Текст Тест Тест Тест Текст Текст Тест Текст Тест Текст. [/ Tag1]
[tag2] Тест в Тест Текст Текст Текст Тест Тест текста.
Тестирование тестового текста Проверка текста «Текст текстового теста» Текст тестового текста.
Тестовый текст? Тестирование текстового теста Текстовый тест Текстовый тест Текстовый тест Текстовый тест Текст.
Test Text, Test Text Test Text Test Text Test Text Test Text Test Text Test Text. [/ Tag2]
....
....
I Я пытаюсь захватить 2 группы в некоторых длинных строках. первый - это текст внутри квадратных скобок, а второй - текст внутри тега.
Регулярное выражение и строка выше не имеют проблем, когда регулярное выражение соответствует. Если в матче, сделанные шаги только 1000+ каждого матча. Но если открывающий и закрывающий теги не совпадают, происходит катастрофическое отступление, и матч заканчивается на 126 000+ шагов и прекращается поиск других соответствующих строк.
Я знаю, что для предотвращения проблемы обратного отслеживания необходимо избегать использования вложенных конструктов с «+» или «*», но я не могу найти лучшего способа сделать это.
Возможно, кто-то может предложить или предложить лучшее регулярное выражение, чем мое?

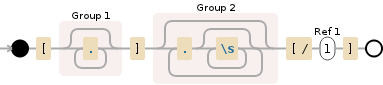

Я не уверен, что понимаю вашу проблему .... Когда возникает проблема? –
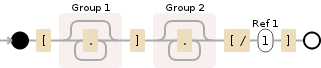
Кроме того, хотя я до сих пор не понимаю вашу проблему, возможно, попробуйте это регулярное выражение? '\ [([^]] +?) \] ([^ [] +) \ [\/\ 1 \]' –
Да, это работает, спасибо. Я просто хочу лучшее регулярное выражение, чем мое, не влияя на производительность позже, когда я применяю его к моему коду. – Ambrose