Во-первых, препроцессировать список вектор, чтобы сделать каждый вектор нормализуется .. единица измерения. Обратите внимание, что теперь функция сравнения T() теперь имеет величины, которые становятся постоянными, и формула может быть упрощена для нахождения наибольшего точечного продукта между вашим тестовым вектором и значениями в базе данных.
Теперь подумайте о новой функции D = расстояние между двумя точками в пространстве 60D. Это классический L2 distance, возьмите разницу между каждым компонентом, соберите квадрат, добавьте все квадраты и возьмите квадратный корень из суммы. D (A, B) = sqrt ((A-B)^2), где A и B представляют собой 60-мерные векторы.
Это может быть расширено, однако, до D (A, B) = sqrt (A * A -2 * dot (A, B) + B * B). A и B - это единица измерения. И функция D монотонна, поэтому она не изменит порядок сортировки, если мы удалим sqrt() и посмотрим на квадратные расстояния. Это оставляет нам только -2 * точку (A, B). Таким образом, минимализующее расстояние точно эквивалентно максимизации точечного произведения.
Таким образом, первоначальная метрика классификации T() может быть упрощена в поиске наивысшего точечного произведения между ноннализованными векторами. И это сравнение эквивалентно обнаружению ближайшего точек точки отсчета в 60-D пространстве.
Итак, теперь все, что вам нужно сделать, это решить эквивалентную проблему «заданной нормированной точкой в пространстве 60D», перечислите 20 пунктов в базе данных нормализованных векторов образца, которые ближе всего к ней ».
Эта проблема хорошо понятна. Это K Nearest Neighbors. Существует множество алгоритмов для решения этой проблемы. Наиболее распространенным является классический KD trees .
Но есть проблема. Деревья KD имеют поведение O (e^D). Высокая размерность быстро становится болезненной. И 60 измерений, безусловно, в этой чрезвычайно болезненной категории. Даже не пытайтесь.
Однако существует несколько альтернативных общих методов для ближайшего соседа высокого D. This paper дает четкий метод.
Но на практике существует отличное решение, включающее еще одно преобразование. Если у вас есть метрическое пространство (которое вы делаете, или вы не будете использовать сравнение Tanimoto), вы можете уменьшить размерность проблемы с помощью 60-мерного вращения. Это звучит сложно и страшно, но это очень распространено. Это форма разложения по сингулярным значениям или разложение по собственным значениям. В статистике он известен как Principal Components Analysis.
В основном это использует простой линейный расчет, чтобы найти, какие направления ваша база данных действительно охватывает. Вы можете свернуть 60 измерений до меньшего числа, возможно, как 3 или 4, и по-прежнему сможете точно определять ближайших соседей. Существует множество программных библиотек для этого на любом языке, например, here.
Наконец, вы сделаете классических ближайших соседей K, возможно, только в 3-10 измерениях. Вы можете поэкспериментировать для лучшего поведения. Для этого есть потрясающая библиотека, которая называется Ranger, но вы можете использовать и другие библиотеки. Отличное преимущество - вам даже не нужно хранить все 60 компонентов ваших данных образца!
Вопрос о том, действительно ли ваши данные могут быть свернуты до более низких измерений, не влияя на точность результатов. На практике разложение PCA может сообщить вам максимальную остаточную ошибку для любого выбранного вами предела D, поэтому вы можете быть уверены, что он работает. Поскольку точки сравнения основаны на метрике расстояния, весьма вероятно, что они сильно коррелированы, в отличие от значений хеш-таблицы.
Так резюме вышеизложенное:
- Нормализация векторов, превращая вашу проблему в K-ближайшие соседи задачу в 60 размерах
- Использование Основных компоненты анализа для уменьшения размерности к управляемому пределу скажем, 5 измерений
- Используйте алгоритм K Nearest Neighbor, такой как библиотека дерева KD Ranger, чтобы найти близлежащие образцы.

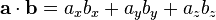
{kind=link}
Вам нужно будет пройти все ваши записи хотя бы один раз, чтобы определить его коэффициент между этим вектором и выбранным вами вектором. –
60 измерений или величина 60? – erickson
Независимо от конечного метода, который вы выбрали для разметки/поиска, вы должны хранить свою базу данных с векторами НОРМАЛИЗИРОВАННАЯ к величине единицы. Это делает любое возможное сравнение простым точечным продуктом, устраняя два измерения амплитуды и деление. – SPWorley