2
У меня есть список нескольких тегов абзаца. Каждый из них без каких-либо атрибутов, например.Как найти последний элемент абзаца?
<p>First paragraph</p>
<p>Second paragraph</p>
<p>Third paragraph</p>
Моя цель состоит в том, чтобы найти последнее открытие <p> тег - независимо от того, если у меня есть только один пункт или десять. Мне всегда нужен тег открытия последнего абзаца.
С
/<p>/
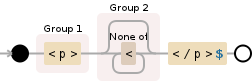
я получаю первый тэг параграфа. Я думал, что $ инвертирует направление поиска слева направо вправо-влево. Таким образом, в основном
/<p>$/
должен вернуть тег абзаца открытия для третьего абзаца из моего примера выше; но регулярное выражение ничего не обнаруживает.
Итак, как наилучшим образом нацелить последний абзац?
обязательный http://stackoverflow.com/questions/1732348/regex-match-open-tags-except-xhtml-self-contained-tags/1732454#1732454 – Jasper
Чтобы быть ясным, вы хотите ** 1) ** последний тег открытия абзаца или ** 2) ** * последний элемент абзаца, начиная с его открывающего тега *? Разница важна, но ** 1) **, кажется, имеет мало смысла, потому что последний тег абзаца открытия ..., конечно, * не отличается от любого предшествующего тега абзаца открытия * в этом случае (если вы не заинтересованы в его индексе внутри входной строки). – J0e3gan
@ j0e3gan я хочу случай 1). Я выполняю 'preg_replace' в функции wordpress. Я хочу применить класс к последнему открытому тегу 'p' и добавить дополнение после. Функция предназначена только для полей плагина ACF с использованием тегов 'p', которые являются только полями wywwg. Я мог бы пойти с оберткой div для полей и использовать: last-child в CSS, но я не поклонник расширения html-разметки. Таким образом, я использую эту функцию только на определенной странице и только на полях wysiwyg, и пользователь может ввести дополнительные абзацы после этого, и класс по-прежнему применяется к каждому последнему тегу 'p'. – rpk