Для программ, которые обрабатывают большое количество соединений сокетов (например, веб-сервисы, системы p2p и т. Д.), Доступно несколько вариантов.Как наиболее эффективно обрабатывать большое количество файловых дескрипторов?
- Создайте отдельный поток для ввода/вывода для каждого гнезда.
- Используйте системный вызов select для мультиплексирования ввода-вывода в один поток.
- Используйте системный вызов poll для мультиплексирования ввода/вывода (замена выбора).
- Используйте системные вызовы epoll, чтобы избежать повторной отправки сокетов fd через границы пользователя/системы.
- Создайте несколько потоков ввода-вывода, каждый из которых мультиплексирует относительно небольшой набор из общего количества соединений с использованием API опроса.
- Согласно №5, за исключением использования API epoll для создания отдельного объекта epoll для каждого независимого потока ввода-вывода.
На многоядерном процессоре я ожидал бы, что # 5 или # 6 будут иметь лучшую производительность, но у меня нет жестких данных, поддерживающих это. В поисковой сети появилась страница this, в которой рассказывается об опыте авторских подходов к тестированию № 2, № 3 и № 4 выше. К сожалению, этой веб-странице, похоже, около 7 лет, без каких-либо очевидных недавних обновлений.
Итак, мой вопрос в том, какие из этих подходов имеют люди, которые считаются наиболее эффективными и/или есть другой подход, который работает лучше, чем любой из перечисленных выше? Будут оценены ссылки на реальные графики, официальные документы и/или доступные в Интернете записи.
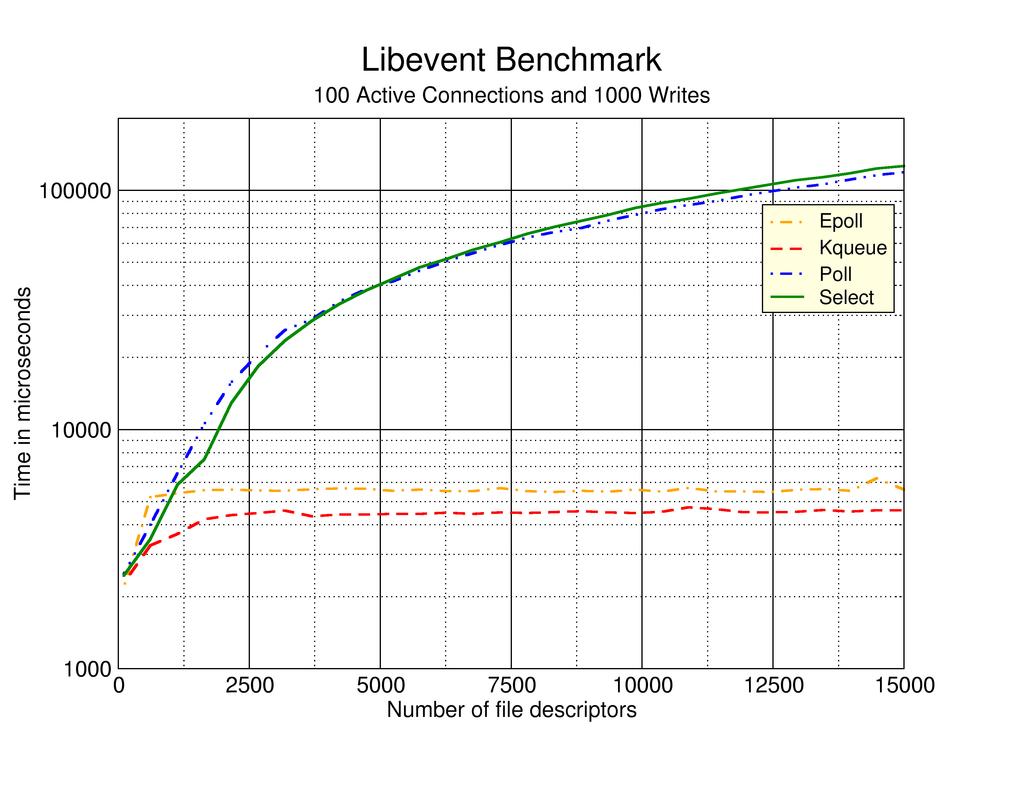 .
.
Я думаю, что это решаемая проблема, и ответ здесь - http://www.kegel.com/c10k.html – computinglife 2008-09-27 01:26:32