Я не уверен, с какими данными вы имеете дело, но вот метод, который я использовал для обработки речевых данных, которые могут помочь вам найти локальные максимумы. Он использует три функции из инструментальной панели обработки сигналов: HILBERT, BUTTER и FILTFILT.
data = (...the waveform of noisy data...);
Fs = (...the sampling rate of the data...);
[b,a] = butter(5,20/(Fs/2),'low'); % Create a low-pass butterworth filter;
% adjust the values as needed.
smoothData = filtfilt(b,a,abs(hilbert(data))); % Apply a hilbert transform
% and filter the data.
Вы бы затем выполнить ваши максимумы нахождение на smoothData. Использование HILBERT сначала создает положительный огибающий данных, затем FILTFILT использует коэффициенты фильтра от BUTTER для фильтра нижних частот для конверта данных.
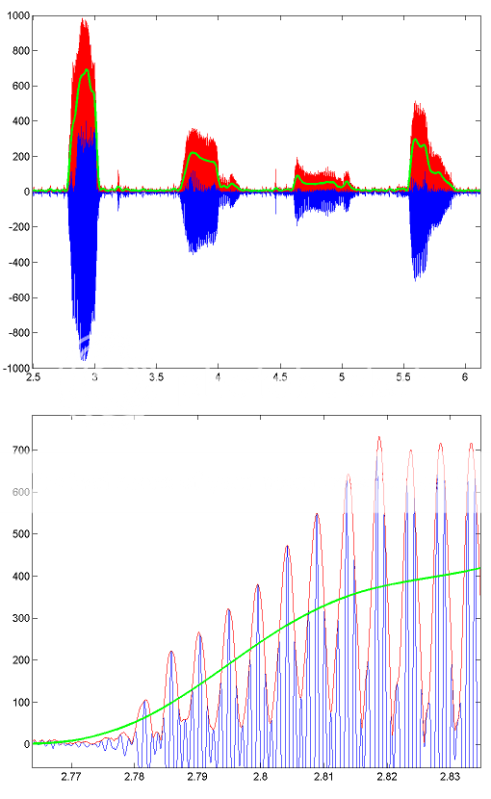
Для примера того, как эта обработка работает, приведены некоторые изображения, показывающие результаты для сегмента записанной речи. Синяя линия - это исходный речевой сигнал, красная линия - конверт (полученная с использованием HILBERT), а зеленая линия - результат фильтрации с низким проходом. Нижняя цифра - увеличенная версия первой.
НЕЧТО RANDOM ПОПРОБОВАТЬ:
Это была случайная идея, которую я имел в первый ... вы могли бы попробовать повторять процесс, находя Maximas из Maximas:
index = find(diff(sign(diff([0; x(:); 0]))) < 0);
maxIndex = index(find(diff(sign(diff([0; x(index); 0]))) < 0));
Однако, в зависимости от отношения сигнал/шум, было бы непонятно, сколько раз это нужно будет повторять, чтобы получить локальные максимумы, которые вас интересуют. Это просто рандо m для нефильтрации. =)
MAXIMA ВЫВОД:
Только в случае, если вам интересно, еще одна линия максимумов ознакомительной алгоритм, который я видел (в дополнение к тому, который был указан) является:
index = find((x > [x(1) x(1:(end-1))]) & (x >= [x(2:end) x(end)]));
Поскольку вы обновили свой вопрос, чтобы сказать, что работаете с изображениями, то уравнение максимума нахождения выше (что более конкретно относится к векторам) может быть не идеальным для вас. Я бы предложил посмотреть на Image Processing Toolbox в MATLAB, если у вас есть к нему доступ. Там могут быть некоторые операции, чтобы помочь вам; просто введите «справочные образы» в MATLAB, чтобы проверить список функций. – gnovice