HTML-парсеры, такие как BeautifulSoup, предполагают, что вы хотите, это объектная модель, которая отражает входную структуру HTML. Но иногда (как в этом случае) эта модель оказывается на пути больше, чем помогает. Pyparsing включает некоторые функции синтаксического анализа HTML, которые более надежны, чем просто использование сырых регулярных выражений, но в противном случае работают аналогичным образом, позволяя вам определять фрагменты HTML-интереса и просто игнорировать остальные. Вот парсер, который читает Опубликованная источник HTML:
from pyparsing import makeHTMLTags,withAttribute,Suppress,Regex,Group
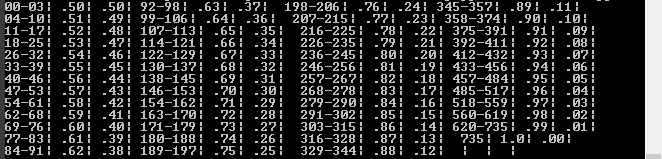
""" looking for this recurring pattern:
<td valign="top" bgcolor="#FFFFCC">00-03</td>
<td valign="top">.50</td>
<td valign="top">.50</td>
and want a dict with keys 0, 1, 2, and 3 all with values (.50,.50)
"""
td,tdend = makeHTMLTags("td")
keytd = td.copy().setParseAction(withAttribute(bgcolor="#FFFFCC"))
td,tdend,keytd = map(Suppress,(td,tdend,keytd))
realnum = Regex(r'1?\.\d+').setParseAction(lambda t:float(t[0]))
integer = Regex(r'\d{1,3}').setParseAction(lambda t:int(t[0]))
DASH = Suppress('-')
# build up an expression matching the HTML bits above
entryExpr = (keytd + integer("start") + DASH + integer("end") + tdend +
Group(2*(td + realnum + tdend))("vals"))
Этот анализатор не только выбирает подходящие троек, он также извлекает старт класса целых и пар действительных чисел (а также уже преобразующий из строки к целым числам или поплавкам во время разбора).
Глядя на стол, я предполагаю, что вам действительно нужен поиск, который займет такой ключ, как 700, и вернет пару значений (0,99, 0,01), так как 700 попадает в диапазон 620-735. Этот бит кода ищет исходный HTML-текст, перебирает соответствующих записей и вставляет пар ключ-значение в Словаре поиска:
# search the input HTML for matches to the entryExpr expression, and build up lookup dict
lookup = {}
for entry in entryExpr.searchString(sourcehtml):
for i in range(entry.start, entry.end+1):
lookup[i] = tuple(entry.vals)
А теперь попробовать несколько подстановочных:
# print out some test values
for test in (0,20,100,700):
print (test, lookup[test])
печатает:
0 (0.5, 0.5)
20 (0.53, 0.47)
100 (0.64, 0.36)
700 (0.99, 0.01)
{kind=link}
Загрузить картину того, как вы хотите, чтобы данные, которые будут представлены в конце концов. +1 для шахматной проблемы. – marlenunez
Он отображает текст в таблице, потому что это то, что делает ваш код. Почему бы вам не нажимать каждое поле в словарь, где ключ является вашим целым числом, а список десятичных знаков - значением? – Blender