2
рассмотрим следующую строку:REGEX для поиска слово, которое не начинается с пространства или закончить с пространством
"abc123 123 123abc abc123abc"
Теперь я хочу, чтобы выбрать 123, что само по себе не. Так что все цифры, но цифры \s\d+\s+
Я попытался кучу вещей, но нет ..

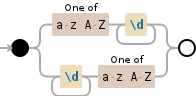
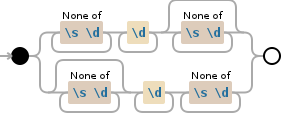
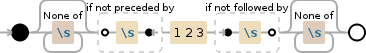
Как бы вы выбрали его? – fzzle