Я пытаюсь запрограммировать приложение для mac, чтобы запросить высокопроизводительный вычислительный кластер о его запущенных и поставленных в очередь задачах расчета. Цель состоит в том, чтобы иметь возможность отслеживать отправленные задания, если они все еще поставлены в очередь и ждут выполнения или если они запущены, и на каком узле или узле в кластере.Как смоделировать систему массового обслуживания HPC с Objective-C
На стороне GUI я хотел бы иметь возможность отображать NSTableView, показывая все отправленное задание, а также второй вариант, чтобы увидеть все хосты в кластере, сколько и какие задания выполняются на каждом узле.
Объекты модели не так уж трудно сделать, что беспокоит меня больше всего - это жизненный цикл и отношения собственности между хостом и объектами задания. Это должно быть хорошо спроектировано, иначе я столкнусь с проблемами управления памятью.
Обратите внимание, что я хотел бы запрограммировать его без использования CoreData, если это возможно.
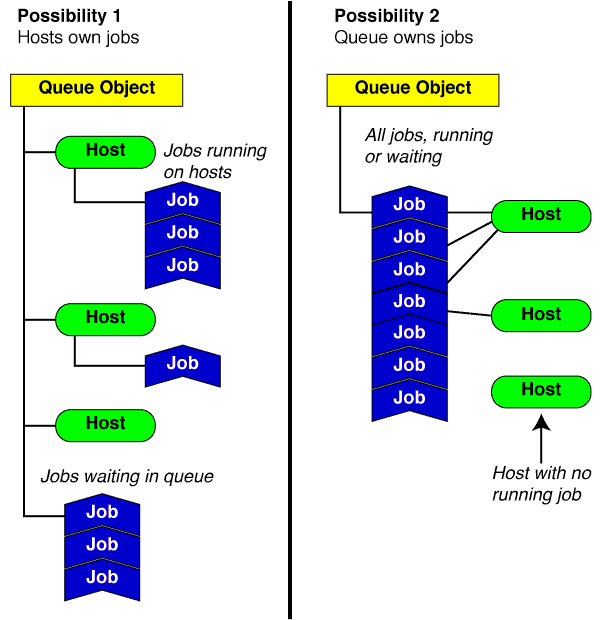
1. Возможность
Желтый объект очереди является корневым объектом моего графа объекта и имеет все принимающие объекты (имеет NSArray объектов пользовательского хоста). Каждому объекту хоста принадлежит весь объект задания, который выполняется на этом хосте (также с помощью NSArray пользовательских объектов задания). Я думаю, что есть два серьезных проблемы с этим подходом:
- где находятся все хранилища объектов заданий, которые все еще находятся в очереди и еще не запущены на хосте. Им не хватает родительского объекта-хозяина.
- Как реализовать объект
NSTableView, содержащий все объекты задания?
2. Возможность
Желтый корень объект содержит непосредственно ссылается на все объекты на работу, имея их хранить в NSArray. Каждое задание имеет переменную экземпляра, сохраняющую объект-хост. Снова вот некоторые проблемы
- У меня также были бы хосты в модели, которые в настоящее время не работают, поэтому на них не выполняется никакая работа.
- Как реализовать источник данных для
NSTableView, отображающий все хосты. - Как убедиться, что нет повторяющихся объектов хоста, так что каждый хост в кластере представлен только одним объектом хоста.
Мои вопросы: 1. Какая из двух возможностей имеет наибольший смысл? Есть ли альтернативы? 2. Можно ли лучше реализовать его с помощью CoreData? 3. Как управлять жизненным циклом объекта, чтобы не было циклов удержания или оборванных указателей.
Спасибо
Вы делаете хорошие моменты об этой проблеме. Я был удивлен, что даже в этом простом примере это не так просто, как я думал, не используя CoreData. Спасибо за ваши мысли. – GorillaPatch
Простые обычно просто означают «знакомые». С моей точки зрения, все это очень «просто» и что-то, что я мог создать буквально через полчаса. У Core Data есть кривая обучения, но как только вы преодолеете «горб», чтобы получить это прямо в голове, тогда это создает проблемы, подобные этому тривиальным. – TechZen