ОК, так, во-первых, вот код с поправками, который поможет вам работать.
#! /usr/bin/python
import numpy as np
def sigmoid(x):
return 1.0/(1.0 + np.exp(-x))
vec_sigmoid = np.vectorize(sigmoid)
# Binesh - just cleaning it up, so you can easily change the number of hiddens.
# Also, initializing with a heuristic from Yoshua Bengio.
# In many places you were using matrix multiplication and elementwise multiplication
# interchangably... You can't do that.. (So I explicitly changed everything to be
# dot products and multiplies so it's clear.)
input_sz = 2;
hidden_sz = 3;
output_sz = 1;
theta1 = np.matrix(0.5 * np.sqrt(6.0/(input_sz+hidden_sz)) * (np.random.rand(1+input_sz,hidden_sz)-0.5))
theta2 = np.matrix(0.5 * np.sqrt(6.0/(hidden_sz+output_sz)) * (np.random.rand(1+hidden_sz,output_sz)-0.5))
def fit(x, y, theta1, theta2, learn_rate=.1):
#forward pass
layer1 = np.matrix(x, dtype='f')
layer1 = np.c_[np.ones(1), layer1]
# Binesh - for layer2 we need to add a bias term.
layer2 = np.c_[np.ones(1), vec_sigmoid(layer1.dot(theta1))]
layer3 = sigmoid(layer2.dot(theta2))
#backprop
delta3 = y - layer3
# Binesh - In reality, this is the _negative_ derivative of the cross entropy function
# wrt the _input_ to the final sigmoid function.
delta2 = np.multiply(delta3.dot(theta2.T), np.multiply(layer2, (1-layer2)))
# Binesh - We actually don't use the delta for the bias term. (What would be the point?
# it has no inputs. Hence the line below.
delta2 = delta2[:,1:]
# But, delta's are just derivatives wrt the inputs to the sigmoid.
# We don't add those to theta directly. We have to multiply these by
# the preceding layer to get the theta2d's and theta1d's
theta2d = np.dot(layer2.T, delta3)
theta1d = np.dot(layer1.T, delta2)
#update weights
# Binesh - here you had delta3 and delta2... Those are not the
# the derivatives wrt the theta's, they are the derivatives wrt
# the inputs to the sigmoids.. (As I mention above)
theta2 += learn_rate * theta2d #??
theta1 += learn_rate * theta1d #??
def train(X, Y):
for _ in range(10000):
for i in range(4):
x = X[i]
y = Y[i]
fit(x, y, theta1, theta2)
# Binesh - Here's a little test function to see that it actually works
def test(X):
for i in range(4):
layer1 = np.matrix(X[i],dtype='f')
layer1 = np.c_[np.ones(1), layer1]
layer2 = np.c_[np.ones(1), vec_sigmoid(layer1.dot(theta1))]
layer3 = sigmoid(layer2.dot(theta2))
print "%d xor %d = %.7f" % (layer1[0,1], layer1[0,2], layer3[0,0])
X = [(0,0), (1,0), (0,1), (1,1)]
Y = [0, 1, 1, 0]
train(X, Y)
# Binesh - Alright, let's see!
test(X)
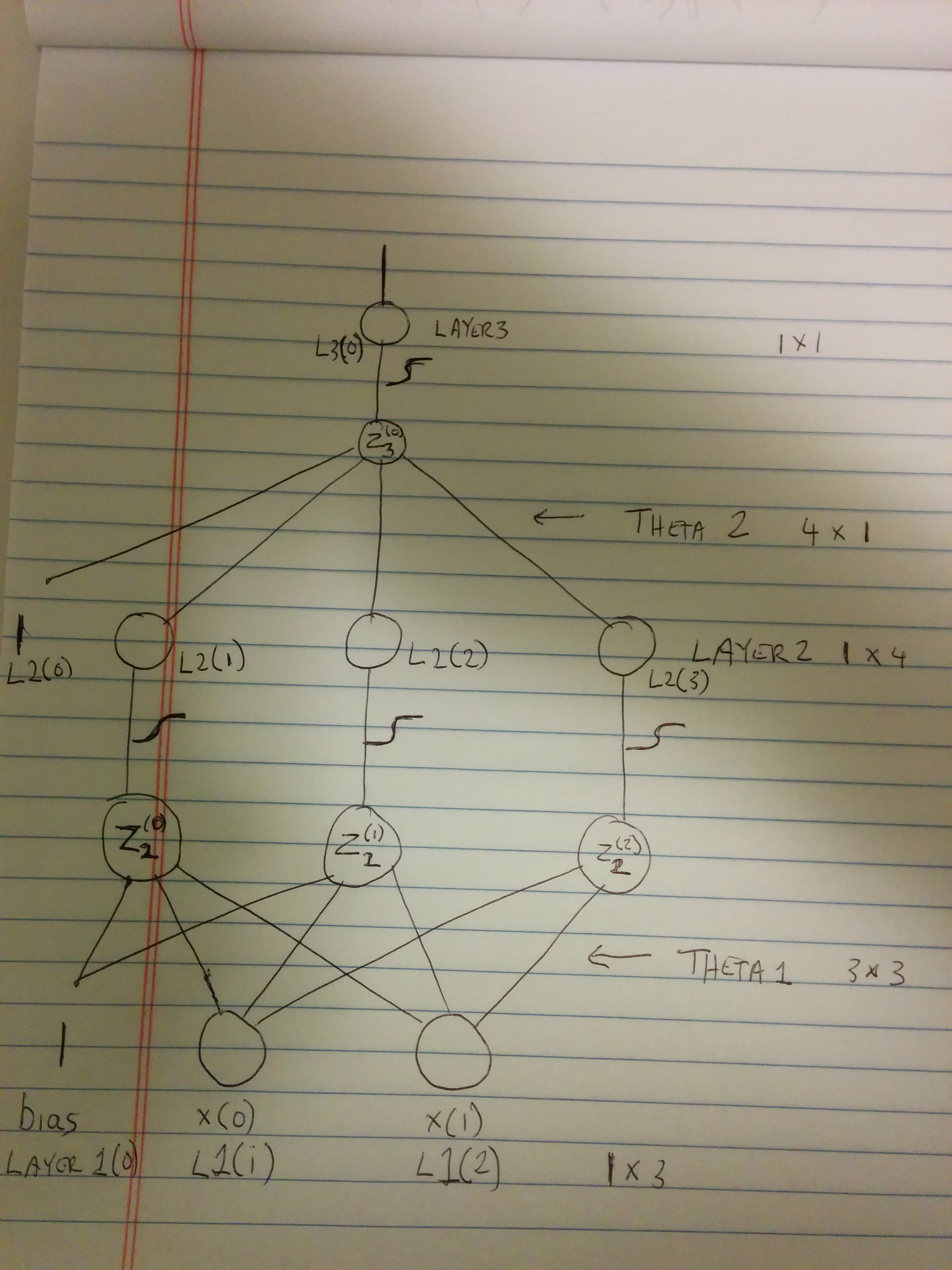
И, теперь для некоторых объяснений. Простите грубый рисунок. Было просто сделать снимок, чем рисовать что-то в gimp.
Visual of WBC's xor neural network http://cablemodem.hex21.com/~binesh/WBC-XOR-nn-small.jpg
Зв Во-первых, у нас есть функция ошибок. Мы будем называть это CE (для кросс-энтропии.Я постараюсь использовать ваши переменные там, где это возможно, tho, я буду использовать L1, L2 и L3 вместо layer1, layer2 и layer3. sigh (Я не знаю, знаю, как сделать латекс здесь. Это, кажется, работает на бирже стека статистики. странно.)
CE = -(Y log(L3) + (1-Y) log(1-L3))
нам нужно взять производную от этой WRT L3, так что мы можем видеть, как мы можем двигаться L3 так чтобы уменьшить это значение.
dCE/dL3 = -((Y/L3) - (1-Y)/(1-L3))
= -((Y(1-L3) - (1-Y)L3)/(L3(1-L3)))
= -(((Y-Y*L3) - (L3-Y*L3))/(L3(1-L3)))
= -((Y-Y3*L3 + Y3*L3 - L3)/(L3(1-L3)))
= -((Y-L3)/(L3(1-L3)))
= ((L3-Y)/(L3(1-L3)))
Отлично, но, на самом деле, мы не можем просто изменить L3, как мы видим, нужным. L3 является функцией Z 3 (См. Мою фотографию).
L3 = sigmoid(Z3)
dL3/dZ3 = L3(1-L3)
Я не вывод этого здесь, (производная от сигмы), но, на самом деле это не так уж трудно доказать).
Но, во всяком случае, это производная от L3 по Z3, но нам нужна производная от CE по Z3.
dCE/dZ3 = (dCE/dL3) * (dL3/dZ3)
= ((L3-Y)/(L3(1-L3)) * (L3(1-L3)) # Hey, look at that. The denominator gets cancelled out and
= (L3-Y) # This is why in my comments I was saying what you are computing is the _negative_ derivative.
Мы называем производные по «дельтам» Z. Таким образом, в вашем коде это соответствует delta3.
Отлично, но мы не можем просто изменить Z3, как нам нравится. Нам нужно вычислить его производную по L2.
Но это сложнее.
Z3 = theta2(0) + theta2(1) * L2(1) + theta2(2) * L2(2) + theta2(3) * L2(3)
Итак, нам нужно взять частные производные по адресу. L2 (1), L2 (2) и L2 (3)
dZ3/dL2(1) = theta2(1)
dZ3/dL2(2) = theta2(2)
dZ3/dL2(3) = theta2(3)
Обратите внимание, что смещение будет фактически
dZ3/dBias = theta2(0)
но смещение никогда не меняется, это всегда 1, так что мы можем спокойно игнорировать Это. Но наш слой2 включает в себя предвзятость, поэтому мы сохраним его пока.
Но, опять же, мы хотим, чтобы производная по Z2 (0), Z2 (1), Z2 (2) (Похоже, я сделал это плохо, к сожалению. Посмотрите на график, с ним будет понятнее, Я думаю.)
dL2(1)/dZ2(0) = L2(1) * (1-L2(1))
dL2(2)/dZ2(1) = L2(2) * (1-L2(2))
dL2(3)/dZ2(2) = L2(3) * (1-L2(3))
Что теперь dCE/dZ2 (0 ..2)
dCE/dZ2(0) = dCE/dZ3 * dZ3/dL2(1) * dL2(1)/dZ2(0)
= (L3-Y) * theta2(1) * L2(1) * (1-L2(1))
dCE/dZ2(1) = dCE/dZ3 * dZ3/dL2(2) * dL2(2)/dZ2(1)
= (L3-Y) * theta2(2) * L2(2) * (1-L2(2))
dCE/dZ2(2) = dCE/dZ3 * dZ3/dL2(3) * dL2(3)/dZ2(2)
= (L3-Y) * theta2(3) * L2(3) * (1-L2(3))
Но, на самом деле мы можем выразить это как (delta3 * транспонировать [theta2]) elemenwise умножается на (L2 * (1-L2)) (где L2 представляет собой вектор)
Они являются наш слой delta2. Я удаляю первую запись, потому что, как я упоминал выше, это соответствует дельтам смещения (что я нахожу L2 (0) на моем графике.)
So. Теперь у нас есть производные по нашим Z, но, действительно, мы можем изменить только те тета.
Z3 = theta2(0) + theta2(1) * L2(1) + theta2(2) * L2(2) + theta2(3) * L2(3)
dZ3/dtheta2(0) = 1
dZ3/dtheta2(1) = L2(1)
dZ3/dtheta2(2) = L2(2)
dZ3/dtheta2(3) = L2(3)
Еще раз Тхо, мы хотим АКД/dtheta2 (0) Тхо, так что становится
dCE/dtheta2(0) = dCE/dZ3 * dZ3/dtheta2(0)
= (L3-Y) * 1
dCE/dtheta2(1) = dCE/dZ3 * dZ3/dtheta2(1)
= (L3-Y) * L2(1)
dCE/dtheta2(2) = dCE/dZ3 * dZ3/dtheta2(2)
= (L3-Y) * L2(2)
dCE/dtheta2(3) = dCE/dZ3 * dZ3/dtheta2(3)
= (L3-Y) * L2(3)
Ну, это просто np.dot (layer2.T, delta3), и вот что Я имею в theta2d
И, аналогично: Z2 (0) = theta1 (0,0) + theta1 (1,0) * L1 (1) + theta1 (2,0) * L1 (2) dZ2 (0)/dtheta1 (0,0) = 1 dZ2 (0)/dtheta1 (1,0) = L1 (1) dZ2 (0)/dtheta1 (2,0) = L1 (2)
Z2(1) = theta1(0,1) + theta1(1,1) * L1(1) + theta1(2,1) * L1(2)
dZ2(1)/dtheta1(0,1) = 1
dZ2(1)/dtheta1(1,1) = L1(1)
dZ2(1)/dtheta1(2,1) = L1(2)
Z2(2) = theta1(0,2) + theta1(1,2) * L1(1) + theta1(2,2) * L1(2)
dZ2(2)/dtheta1(0,2) = 1
dZ2(2)/dtheta1(1,2) = L1(1)
dZ2(2)/dtheta1(2,2) = L1(2)
И мы должны умножить на АКД/dz2 (0), DCE/dz2 (1) и АКД/dZ2 (2) (для каждой из трех групп там. Но, если вы подумаете об этом, тогда просто станет np.dot (layer1.T, delta2), и это то, что у меня есть в theta1d.
Теперь, поскольку вы сделали Y-L3 в своем коде, вы добавили в theta1 и theta2 ... Но вот рассуждение. То, что мы только что вычислили выше, является производной от CE по весам. Таким образом, это означает, что увеличение весов по желанию увеличить CE. Но мы действительно хотим уменьшить CE .. Итак, мы вычитаем (обычно). Но, поскольку в вашем коде вы вычисляете отрицательную производную, это правильно, что вы добавляете.
Это имеет смысл?
{kind=link}
Большое вам спасибо, я просмотрю это и на бумаге. трудно ли векторизовать ввод, чтобы избежать внутреннего цикла через X? – WBC
О, определенно нет. Здесь вы проходите в X как вектор 1x2 (который становится 1x3 с уклоном), и вы умножаете (** dot product **), который умножает матрицу 3x3, чтобы получить выход 1x3 для трех узлов в layer2, справа ? Все, что вам нужно сделать, вместо этого передать все 4 элемента X в виде 4x2-вектора (который вам нужно будет добавить вектор смещения, чтобы сделать его 4x3), и вы используете точечный продукт, который умножает матрицу 3x3, чтобы получить 4x3 для трех узлов в слое2. Вы делаете то же самое и над слоем 3, и вы получите 4x1, и все цели будут происходить одновременно ... – bnsh
Hm. По-видимому, я не могу опубликовать весь код здесь. Но это очень просто для векторизации. Во-первых, после того, как layer1 = np.matrix (х, DTYPE = 'F') добавить у = np.matrix (у, DTYPE = 'е'). Т (м, SZ) = layer1.shape Измените np.ones (1) на np.ones (m) в обоих местах. и сделать поезд будет: Защита поезда (X, Y): для _ в диапазоне (10000): годных (X, Y, theta1, theta2) я не изменял тест, но это должно быть достаточно легко. (Запуск символов для комментария, хе-хе ...) – bnsh